The Line Between AI As "Fancy Software" And Cloud Infrastructure Is Blurred
Posted
AI Isn’t Magical—Just Well-Autoscaled Software
Behind every AI-powered chatbot, image generator, or content engine lies layers of software, data pipelines, and cloud infrastructure. It's not sorcery. It’s GPU compute cycles, APIs, and autoscaling groups. And yes, it lives in “the cloud,” not on some sentient mainframe deep in a bunker.
When you ask ChatGPT for help writing an email, you're not tapping into an oracle. You're using fancy software running on servers that get hot, break, or just hit their quotas. If you have pushed the models hard you inevitably run into a message like “It seems like I can’t do more advanced data analysis right now. Please try again later.”
How AI Really Runs
Today’s AI tools are cloud-native by default. They’re trained, hosted, and served via hyperscale infrastructure. And the numbers tell a story of explosive growth:
- AI developer services market: $14.4B in 2024 → projected $52.5B by 2033 (15.2% CAGR)
- Cloud GPU market: $3.2B in 2023 → expected $47.2B by 2032 (35% CAGR)
"Cloud service providers provide compute at deep discounts to large AI research labs..."
— AI Now Institute
In short: AI isn’t just running on the cloud. It is the cloud now.
Only a Handful of Players Run the Show
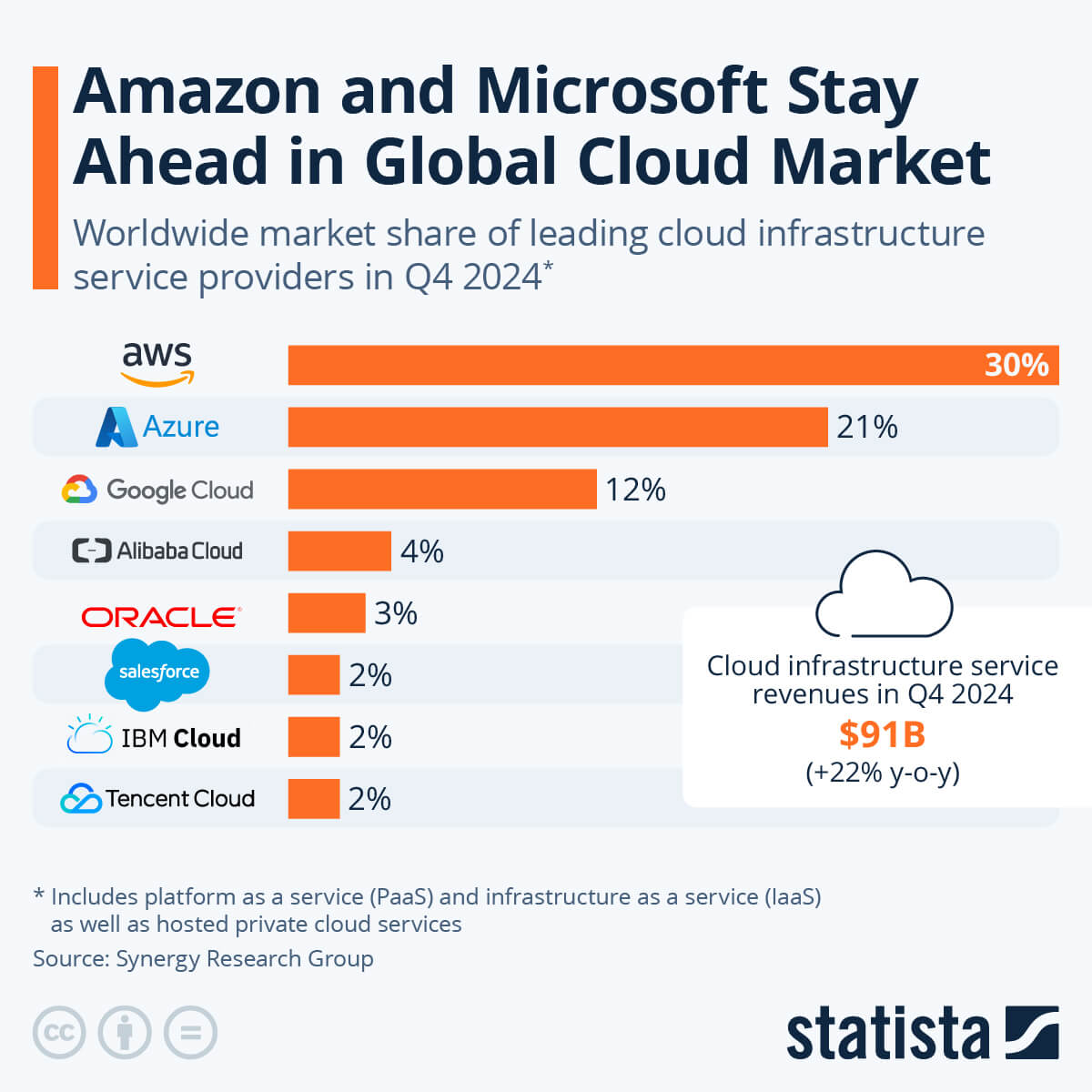
Let’s talk centralization. About 60–70% of all global cloud workloads live in the hands of just three companies:
- Amazon Web Services (AWS): ~30%
- Microsoft Azure: ~22%
- Google Cloud Platform (GCP): ~11%
"Switching friction, bundled services, and data migration costs are reinforcing provider lock-in..."
— OECD Competition Report, 2025
This isn't just a monopoly problem. It's a resilience problem.
The ChatGPT Meltdown: June 2025
On June 10–11, 2025, ChatGPT suffered a 34-hour outage that cascaded across all tiers—free and paid users alike.
What happened:
- 4.2 million requests per minute, 37% higher than any prior peak.
- Load balancer cascade failure, causing microservices to time out.
- Regional overload in the EU, cascading globally due to rerouting delays.
"This was not a model issue. This was infrastructure fragility at scale."
Real-world impact:
- 27% of enterprise dev teams reported code deployment delays
- 32% of marketing teams paused campaigns
Thousands reported issues. OpenAI called it "degraded performance." Twitter called it a blackout.
This Wasn’t an AI Problem. It Was an Infrastructure Problem.
AI services fail not because they forget how to predict your next token. They fail whenload balancers buckle, regions overload, or GPU quotas max out.
The problem isn’t that AI is unreliable. The problem is that we forget that it’s software. And software, at scale, is vulnerable to:
- Vendor quotas
- Resource contention
- Network partitioning
Business-Critical Workflows Need Real Governance
AI has moved beyond playground use cases:
- Customer support bots
- Marketing content generation
- DevOps co-pilots
Yet many businesses:
- Don’t leverage the SLAs that are in place
- Rely on single-vendor infrastructure
- Lack observability into AI service performance
"69% of IT leaders experienced cloud budget overruns in 2024."
— Gartner
Outages like ChatGPT’s show how a single infrastructure layer failure can knock out business operations globally.
Final Thought (With a Wink)
Think of AI like your office espresso machine. It’s fancy, helpful, and makes everyone more productive. But if it breaks on Monday morning?
Panic.
So the next time someone says AI will take over the world, just smile and say:
"Only if its load balancer doesn’t time out first."
AI may be fancy software, but it’s still software. And when the cloud it rides on fails, your mission-critical workflows go with it.
It’s time to start treating AI not like magic—but like the software infrastructure it really is.